

Você acredita na ideia de que, uma vez que algo é publicado na Internet, é publicado para sempre? Bem, hoje vamos dissipar esse mito.
A verdade é que, em muitos casos, é perfeitamente possível erradicar informações da Internet. Claro, há um registro de páginas da web que foram deletadas se você pesquisar na Wayback Machine, certo? Sim, absolutamente. Na Wayback Machine existem registros de páginas da web que remontam a muitos anos - páginas que você não encontrará em uma pesquisa do Google porque a página da web não existe mais. Alguém o excluiu ou o site foi desativado.
Então, não há como fugir disso, certo? A informação será gravada para sempre na pedra da Internet, lá para as gerações verem? Bem, não exatamente.
A verdade é que, embora seja difícil ou impossível eliminar grandes notícias que proliferaram de um site de notícias ou blog para outro como um vírus, é realmente muito fácil erradicar completamente uma página da web ou várias páginas da web de todos os registros. de existência - para remover essa página para ambos os motores de busca, bem como a Wayback Machine A nova Wayback Machine permite-lhe viajar visualmente no tempo da Internet A nova Wayback Machine permite-lhe viajar visualmente no tempo da Internet Parece que desde o lançamento do Wayback Machine em Em 2001, os proprietários do site decidiram lançar o back-end baseado no Alexa e redesenhá-lo com seu próprio código-fonte aberto. Depois de realizar testes com o ... Leia Mais. Há uma pegadinha, claro, mas vamos chegar a isso.
3 maneiras de remover páginas do blog da rede
O primeiro método é aquele que a maioria dos proprietários de sites usa, porque eles não conhecem nada melhor - simplesmente excluindo páginas da web. Isso pode acontecer porque você percebeu que tem conteúdo duplicado em seu site ou porque tem uma página que não deseja exibir nos resultados da pesquisa.
Basta excluir a página
O problema de excluir totalmente as páginas do seu website é que, como você já estabeleceu a página na rede, provavelmente haverá links do seu próprio site, além de links externos de outros sites para essa página específica. Quando você exclui, o Google reconhece imediatamente essa página como uma página ausente.
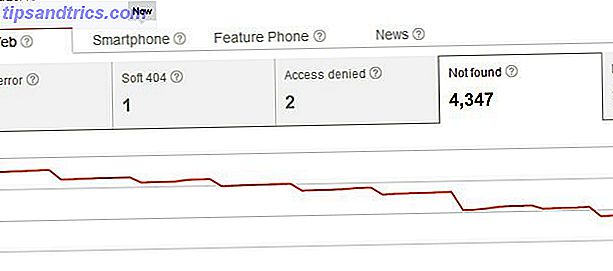
Assim, ao excluir sua página, você não apenas criou um problema com os erros de rastreamento "Não encontrado", mas também criou um problema para qualquer um que já tenha vinculado a página. Normalmente, os usuários que acessam seu site a partir de um desses links externos verão sua página 404, o que não é um grande problema, se você usar algo como o código 404 personalizado do Google para oferecer sugestões ou alternativas úteis aos usuários. Mas, você pensaria que poderia haver maneiras mais graciosas de excluir páginas dos resultados de pesquisa sem chutar todos os 404s para os links recebidos existentes, certo?
Bem, existem.
Remover uma página dos resultados de pesquisa do Google
Em primeiro lugar, você deve entender que, se a página da web que você deseja remover dos resultados de pesquisa do Google não for uma página do seu próprio site, você estará sem sorte, a menos que haja motivos legais ou caso o site tenha publicado informações on-line sem sua permissão. Se esse for o caso, use o solucionador de problemas de remoção do Google para enviar uma solicitação para que a página seja removida dos resultados de pesquisa. Se você tiver um caso válido, o seu pode encontrar algum sucesso com a página removida - é claro que você pode ter sucesso ainda maior apenas contatando o dono do site Como remover informações pessoais falsas na Internet Como remover informações pessoais falsas na Internet Leia mais como descrevi como fazer em 2009.
Agora, se a página que você deseja remover dos resultados da pesquisa estiver em seu próprio site, você está com sorte. Tudo o que você precisa fazer é criar um arquivo robots.txt e garantir que você não tenha permitido a página específica que você não deseja nos resultados da pesquisa ou o diretório inteiro com o conteúdo que você não deseja indexar. Aqui está o que bloqueia uma única página parece.
User-agent: * Disallow: /my-deleted-article-that-i-want-removed.html
Você pode impedir que bots rastreiem diretórios inteiros do seu site da seguinte maneira.
User-agent: * Não permitir: / content-about-personal-stuff /
O Google tem uma excelente página de suporte que pode ajudá-lo a criar um arquivo robots.txt, caso você nunca tenha criado um antes. Isso funciona muito bem, como expliquei recentemente em um artigo sobre como estruturar sindicatos de ofertas Como negociar ofertas de sindicação e proteger seus rankings de pesquisa Como negociar ofertas de sindicação e proteger seus rankings de pesquisa Syndicating é toda a raiva nos dias de hoje. Mas, de repente, você pode descobrir que o parceiro de distribuição está listado mais alto do que você nos resultados de pesquisa de uma história que você originalmente escreveu! Proteja seus rankings de busca. Leia mais para que eles não o machuquem (pedindo a parceiros de distribuição para não permitir a indexação de suas páginas onde você é sindicado). Depois que meu próprio parceiro de distribuição concordou em fazer isso, as páginas que eram conteúdo duplicado do meu blog desapareceram completamente das listagens de pesquisa.

Apenas o site principal aparece em terceiro lugar na página onde eles listam nosso título, mas meu blog agora está listado no primeiro e no segundo ponto; algo que seria quase impossível se um site de autoridade superior deixasse a página duplicada indexada.
O que muitas pessoas não percebem é que isso também é possível com o Internet Archive (a Wayback Machine) também. Aqui estão as linhas que você precisa adicionar ao seu arquivo robots.txt para que isso aconteça.
User-agent: ia_archiver Não permitir: / sample-category /
Neste exemplo, estou dizendo ao Internet Archive para remover qualquer coisa no subdiretório de categoria de amostra em meu site da Wayback Machine. O arquivo da Internet explica como fazer isso na página de ajuda Exclusão. É também aí que eles explicam que “o Internet Archive não está interessado em oferecer acesso a sites ou outros documentos da Internet cujos autores não querem seus materiais na coleção”.
Isso contraria a crença comum de que qualquer coisa postada na Internet é arrastada para o arquivo por toda a eternidade. Não - os webmasters que possuem o conteúdo podem especificamente remover o conteúdo do arquivo usando a abordagem robots.txt.
Remover uma página individual com metatags
Se você tem apenas algumas páginas individuais que deseja remover dos resultados da Pesquisa do Google, na verdade, você não precisa usar a abordagem robots.txt, basta adicionar a metatag "robôs" correta às páginas individuais, e diga aos robôs para não indexarem ou seguirem links em toda a página.

Você pode usar a meta dos "robôs" acima para impedir que os robôs indexem a página ou dizer especificamente ao robô do Google para não indexar, para que a página seja removida dos resultados de pesquisa do Google e outros robôs de pesquisa ainda possam acessar o conteúdo da página.
Cabe a você decidir como você deseja gerenciar o que os robôs fazem com a página e se a página é listada ou não. Para apenas algumas páginas individuais, essa pode ser a melhor abordagem. Para remover um diretório inteiro de conteúdo, use o método robots.txt.
A ideia de "remover" o conteúdo
Isso transforma toda a noção de “excluir conteúdo da Internet” de cabeça para baixo. Tecnicamente, se você remover todos os seus próprios links para uma página em seu site e removê-los da Pesquisa do Google e do Arquivo da Internet usando a técnica do robots.txt, a página será, para todos os efeitos, "excluída" da Internet. O legal é que, se houver links existentes para a página, esses links ainda funcionarão e você não acionará erros 404 para esses visitantes.
É uma abordagem mais “gentil” para remover conteúdo da Internet sem atrapalhar totalmente a popularidade existente de links do site em toda a Internet. No final, como você gerencia o conteúdo coletado pelos mecanismos de pesquisa e o Internet Archive, você sempre se lembra de que, apesar do que as pessoas dizem sobre a vida útil das coisas postadas on-line, elas estão completamente sob seu controle. .